contents: a taxonomy of models | twitter sentiment analysis | ramblings on ideology and utilitarianism
TL; DR: I propose that we can categorize models into top-down and bottom-up approaches, and discuss the implications of tinkering with this categorization.
When you’re building a model of the world, should you build it by deducing from first principles, or should you build it by seeing if you can spot patterns in your observations? Will these two approaches lead to the same thing?
This summer, I did CUEA’s AI Safety Fellowship to learn more about AI alignment—massive thanks to Gabe and Rohan for moderating the group and proofreading this post! In this post, I talk about my insights from reading about alignment (see syllabus for reading list) and training my first deep learning model. I also describe my mental model for broadly categorizing approaches to the “pursuit of truth,” and the impact of taking this approach on AI safety.
initial taxonomy of AI
Richard Ngo categorizes ML broadly into 2 things: Symbolic AI and ML. After reading his post and a few others on the current landscape in AI from the reading group syllabus, I created an initial “map of the territory” (hopefully I don’t destroy it):
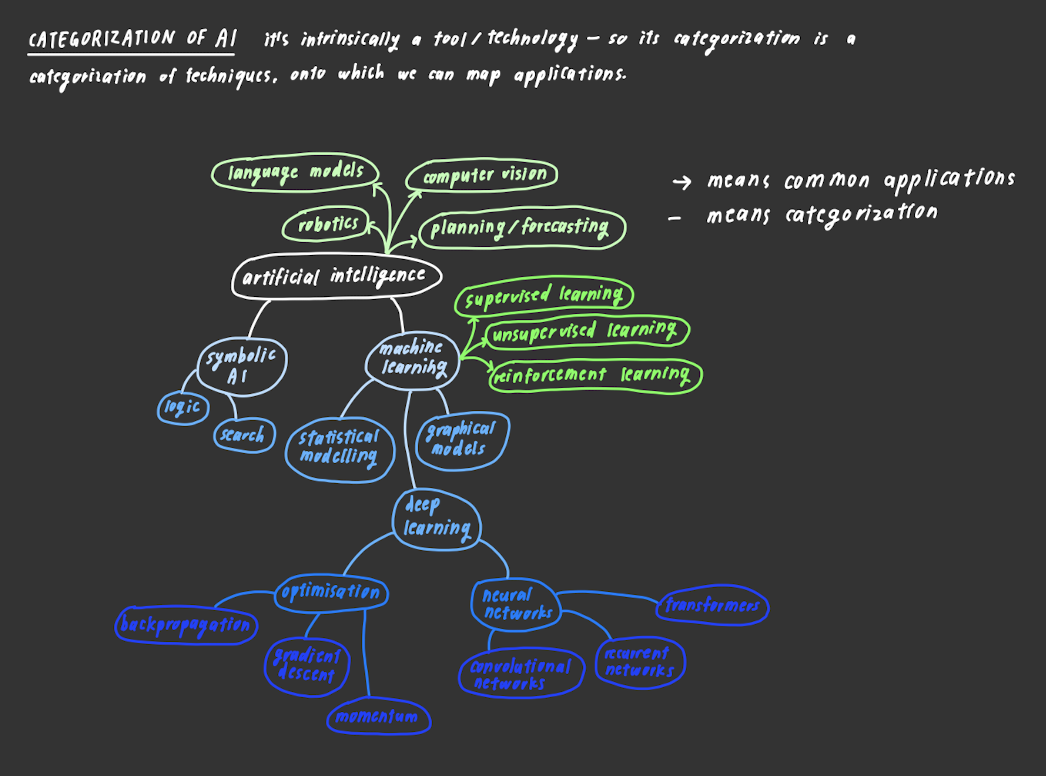
towards a generalized taxonomy of models
This structure is still how I think about AI: Symbolic AI starts from the bottom-up, working from formal systems and logical reasoning to deduce truths. ML and deep learning, on the other hand, start top-down, leveraging computational power to find relationships in data. The existence of two orthogonal approaches to the pursuit of truth is not unique to AI. Most times when we have any question on the true nature of things, there will be two ways to answer it:
In cognition: How do humans make sense of the world? From structure (structuralism; a posteriori) vs. from first principles (a priori)
In logic: How do we reason? Using deduction (analytic or, in the words of Korzybski, Aristotelian intension) vs. using observation/induction (synthetic, or non-Aristotelian extension)
In physics: How should we tackle model selection/phenomenology? Top-down vs. bottom-up construction
In finance: How big is my total addressable market? Market sizing from population demographics (top-down) vs. from customer segment growth (bottom-up)
In algorithm analysis: How do I design an algorithm? Top-down (recursively) vs. bottom-up (iteratively)
& many more isomorphisms

Am I painting a false dichotomy? Yes!: Obviously, we use both approaches to construct models (abduction, synthetic a priori, …). In other words, orthogonality doesn’t imply mutual exclusivity. Also, even within each framework, there are significant grounds of disagreement. Take modern statistics, for example: Even after you accept that you can reason from data (i.e: accept inductive reasoning), the way you treat it still assumes a position in the Fisherian significance testing vs. Neyman-Pearson hypothesis testing vs. Bayesian inference debate. So this is all to say: Yes, nuance.
(Also, in case there’s confusion—by “orthogonality,” I am referring to general orthogonality/linear independence rather than the orthogonality thesis.)
Why does this matter? I believe that, if we explicitly recognize the common structure underlying all of these different fields, we can map insights from one to the other. In other words, we can construct a reference class/do some meta-pattern recognition. Also, just because our territory is nuanced doesn’t mean that making a simplified mental model is futile.
First, I think it’s worth pondering the initial questions this model begs:
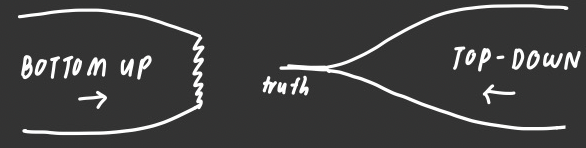
1: Do top-down and bottom-up approaches actually converge to the truth?: In the diagram I drew, the top-down and bottom-up approaches converge to truth. This is the same thing as saying: “Asymptotically, both approaches are systematically unbiased models for truth,” or: “truth exists, and our approaches can find it.” Is this necessarily the case? Let’s play this out…

(A) Yes, they will converge. They will converge at…
The universal truth: This is like a teleology of sorts for truth. Maybe the middle is some ideal amazing perfect Platonic world filled with mathematical truths and proofs from the book. If universal truth exists and is reachable by our current methods, does it mean that everything has been determined from the beginning? (This is a common sentiment, but I don’t think it’s true: I don’t think that the existence of the mean implies the non-existence of variance.)
Something untrue: We’re missing something crucial, and all of our methods are guiding us into a trajectory of doing something terribly wrong. Why? And will we even be able to tell? (In market sizing, both top-down and bottom-up approaches are heavily prone to overestimation—is this tendency generalizable to the overarching structure?)

(B) No, they will not converge, because…
1. Each approach will give us a different answer: This suggests that one or both of these approaches has systematic bias that’s different from the other’s. Where are the sources of these biases, and is there a way of determining which one is less biased? How will we be able to tell?

2. Deductive reasoning will never lead us to truth: Maybe the idea of starting with formal systems and logic is flawed in the first place. Maybe we should listen to Tarski when he gives us a theorem on the non-definability of truth, or Gödel, when he showed incompleteness, and give up romantic preoccupations like logicism or translating math into Lean. (This post was written by a romantic—at least I’m self-aware!)
3. Inductive reasoning from data will never lead us to truth: There is a missing shade of blue. I think there’s a lot of debate on why formal systems won’t lead us to truth, but not enough emphasis on the fundamental contradictions in modern statistics and data science (see: Clayton’s Bernoulli’s Fallacy, Ioannidis’ “Why Most Published Research Findings are False”). This is especially dangerous because ML, like quantum mechanics, seems to hold this luster of intentional, declared complexity. Such a widespread declaration of profundity and difficulty leads to systematic over-reliance.
“The scientific method is really complicated, so whatever it produces, we know it’s right. The scientists know what they’re doing.” ⚠️ ⚠️

4. They will not converge because truth doesn’t exist: This is, surprisingly, a popular view. I don’t yet know how to address this, but am personally against it for many reasons (reasons 1, 2, and 2.5).
→ The bottom line: At least thinking about the space of possibilities >> mistaking neutrality for wisdom.
2: If we accept that truth exists and both ways will get us there, where are we right now?
In AI, ML has done much better than symbolic AI in the past few decades. While formal systems were being shaken up by paradoxes and incompleteness, computational power has advanced by leaps and bounds, allowing deep learning to solve the protein folding problem and classify images. Our current progression is undoubtedly asymmetric:

→ this might lead us to think that top-down approaches are better than bottom-up ones, but it doesn’t necessarily follow. As per B3, we should not be blinded by statistics or think that extracting information from a deluge of data is infallible.
3: What are the implications of thinking about things this way?:
Model evaluation: We should call models what they are. GPT-3 is a model that’s bad at math, but its creation comes from somewhere diametrically opposite the use of formal reasoning. It’s unfair to say that GPT-3 is stupid because it’s not Wolfram Alpha, although it might be funny. It’s also unfair to say that Wolfram Alpha is stupid because it doesn’t understand that exp(x) ≠ e·x·p·x, although it might be funny.
Once we correctly characterize approaches by their nature, we can see the problems inherent in each approach. For example: Bottom-up approaches are too reliant on their starting axioms, and top-down approaches are, by definition, difficult to interpret and too reliant on the set of data used to train it.Artificial general intelligence: A possible definition of AGI naturally arises from this, as an entity that knows every aspect of reality that’s true (or, correctly estimates the distribution of all events). Alternatively: An entity that knows these distributions better than human experts for each field. How will it get there? Should the way we tackle alignment be different depending on how AGI is reached (from one side vs. the other vs. a combination)?
Or, perhaps more interestingly: Say deep learning models get us AGI. Will it then be able to evaluate things positioned more on the other side, about formal systems? I think that such a bridge exists, and that the link is algorithm analysis: Every time we understand a property well enough, we kind of have a polynomial-time algorithm to determine whether it holds. Like minimum spanning trees ⇔ Kruskal’s algorithm, and isomorphic graphs ⇔ the lack of an algorithm. What I’m trying to say is: If we attain AGI through deep learning, we might be able to deduce truths about formal systems by evaluating algorithms.Alignment: Since the approaches are orthogonal, we can be much more confident in our models if they suggest the same thing. Ideally, we can use both approaches—this allows us to avoid the worst-case scenarios of every possibility in 1B.
The bottom line: There are many ways to think about how we model the world. I found that tinkering with this particular way was rewarding, and had good explanatory power in thinking about the forest (pun intended) of advances in AI.
twitter sentiment analysis
I’d have a guilty conscience if I wrote a blog post about ML without doing some sort of data analysis. So I did something kind of fun: I wanted to see if there was a relationship between the price-to-earnings (P/E) ratios and recent Twitter sentiments for the 30 companies in the Dow Jones (because 30 is a tractable number—500, on the other hand…). The P/E ratio is a company’s stock price divided by how much net income they’re making per share (EPS). It’s one of the value multiples you can use to evaluate a company.
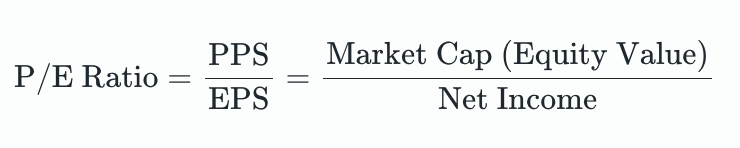
x-period P/E: “How much money do I have to spend for every dollar of x-period earnings?”
Why would a company have a high P/E ratio? → Lots of reasons, but mainly growth assumptions: If we think a company will make a lot more money in the future, we’re willing to pay more for it relative to their earning power today. We tend to pay more for tech stocks than blue chips. In other words, P/E ratios tend to be higher for companies with more favorable growth prospects.
So… Does positive investor sentiment in the form of higher P/E ratios correspond to positive Twitter sentiment? No, not really, at least for the 30 companies in the DJI and based on Tweets retrieved Sept 2–3 2022.
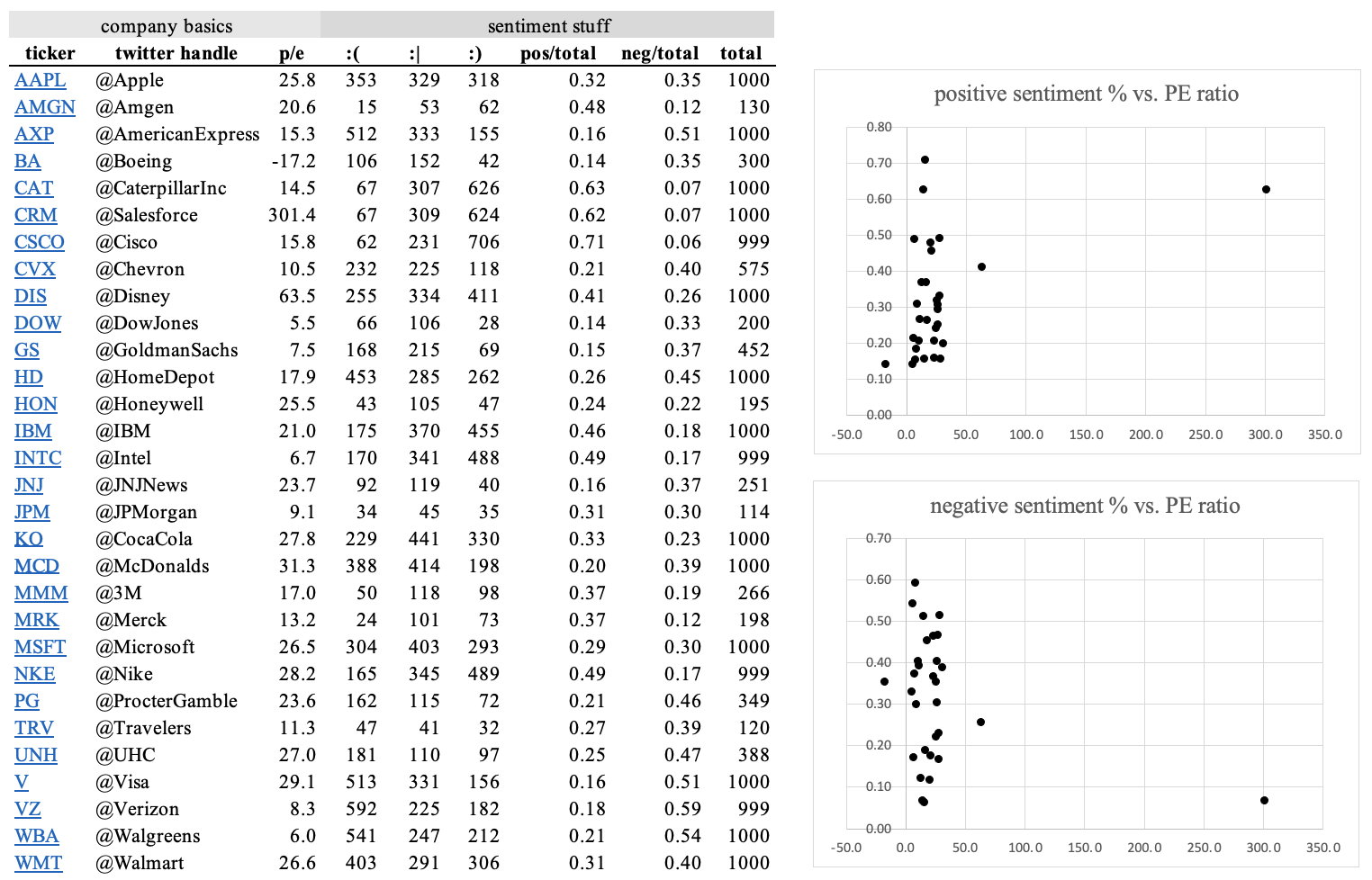
Nuance: P/E ratios have a much stronger relationship with the industry a company is in; the companies in the DJI aren’t your typical growth stock; Twitter sentiment measures consumer experience, which doesn’t perfectly translate to growth assumptions; some companies like Boeing aren’t consumer-facing; Twitter bots; survivorship bias; some companies have greater Twitter presence, etc…
But it was quite fun to run regardless! Also, if you’d like to download the Tweet data or do something similar, here is…
RAMBLINGS ON IDEOLOGY AND UTILITARIANISM
Ramblings on ideology: I mean to establish the search for truth as something fundamentally separate from ideology (like psychoanalytic theory or Kant’s categorical imperative). Ideology is a lens which assigns value and attaches meaning to signs; it is, by definition, not falsifiable. Ideology should not be conflated with theories in the search for truth—nor is it fair to evaluate ideology based on criterion for falsifiability. (Pet peeve: “Kant sucks because his theories aren’t falsifiable!” Dude, are they supposed to be?)
Ramblings on utilitarianism: It’s unfair to say that utilitarianism is the ideological framework of effective altruism, but I think that utilitarian ideas have a strong grasp on not only EA, but also modern liberalism. This means that some problems in EA and liberalism fundamentally stem from problems with utilitarianism. For example: Since utilitarianism implies some sort of linear ordering of utility, the most common critique of it involves constructing a degenerate case out of the ordering, like the ethics of having sex with a dead chicken (mentioned by Louise Perry in The Case Against the Sexual Revolution). The idea that utilitarianism “poisons” EA is a common critique of EA (see: Erik Hoel’s “Why I am not an effective altruist”).
My thoughts: You can attack anything by attacking its ideological foundations. You can attack any ideology by proposing a degenerate case that conflicts with intuition/heuristics (e.g: “would you lie to save a life” vs. Kantian deontology). What’s the way out here? I guess when you’re constructing a personal ideology, you could scrap together some combination of different ideologies that you feel okay about given their degenerate cases. But that’s not incredibly rigorous or systematic, is it? Should it necessarily be/not be this way?